
Stats Speak for Themselves
98%User Satisfaction
5M+Pre-Assessed Candidates in Pool
4.9Average Reviews
27+Integrations
Recruiters' #1 Choice For Better Candidate Engagement










Data-Driven Excellence
Our robust data-driven approach offers unparalleled insights into your talent landscape. Utilizing descriptive, predictive, and prescriptive analytics combined with domain expertise, we craft actionable strategies to address your talent acquisition challenges.


Insightful Data Analytics
Access unparalleled insights into candidate behavior, supported by automated processes that harness data from career sites, performance metrics, and a daily influx of millions of job seekers.

Career Site Network
Tap into a wealth of data from our extensive network of enterprise career sites, encompassing multiple platforms attracting millions of applicants annually.

Performance Metrics
Augment your insights with enriched performance data covering employer reputation, firm size, sector, wages, hours worked, unemployment rates, and population demographics.
An ATS designed with advanced AI data models to forecast on-the-job performance
We assist companies in enhancing their talent decisions with a modern and experiential ATS suite. Our solution enables quick measurement of job-relevant skills and proficiencies for smarter and faster decision-making.
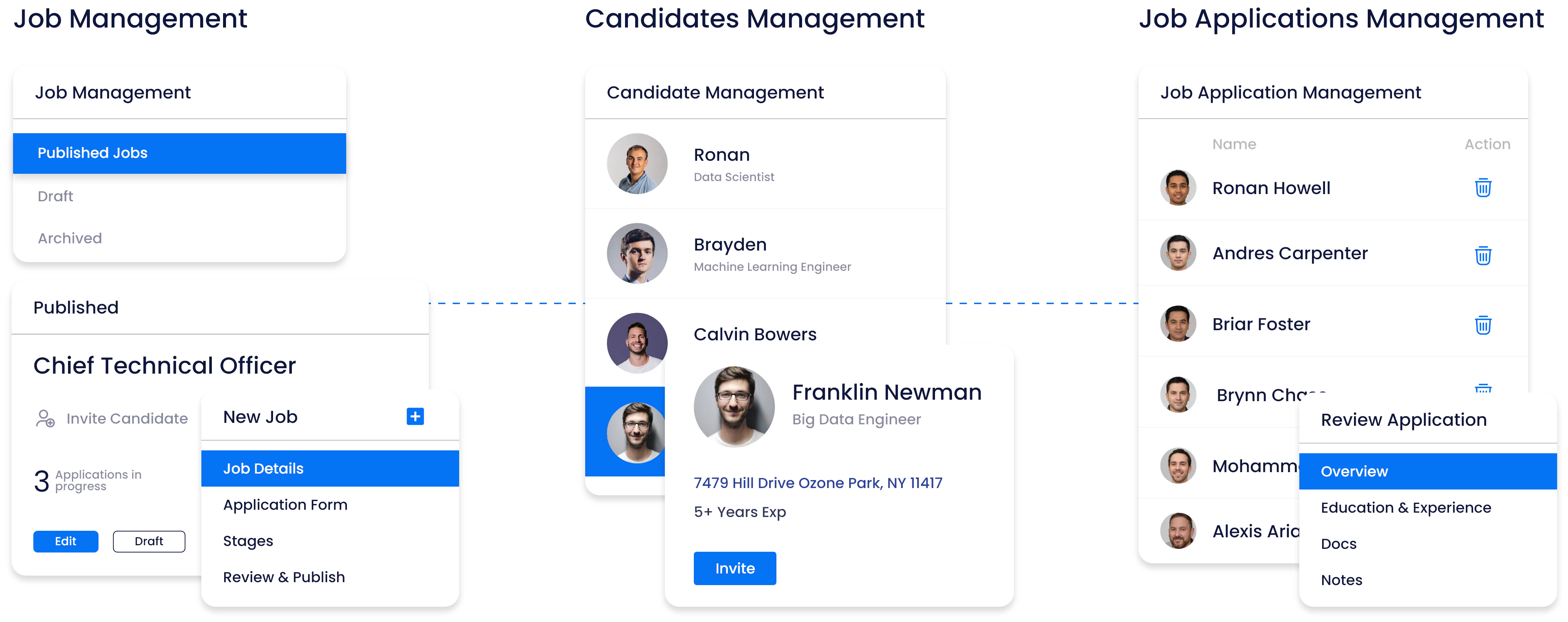
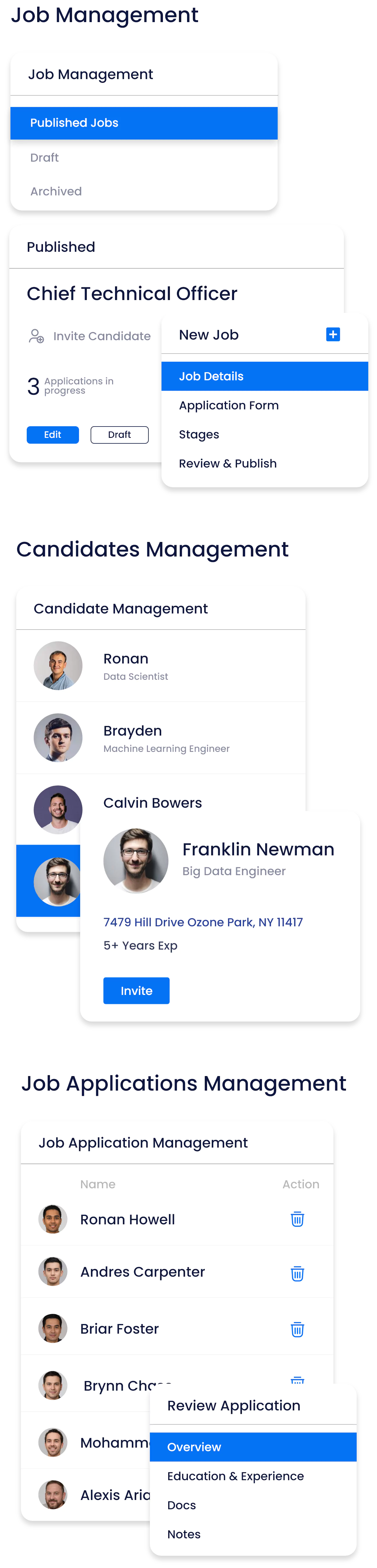
Make hiring decisions based on candidate performance metrics, eliminating bias.

Expand Reach
Effectively target suitable talent using a platform that dynamically adjusts job visibility across various tactics and channels for optimal performance.
Optimize Interaction Points
Provide personalized branded experiences throughout the candidate journey, utilizing user engagement and network intelligence to enhance success.
Boost Operational Efficiency
Harness data-driven automation and insights to target high-quality talent, streamline processes, and decrease the volume of applications required for successful hires.
Branded Career Page
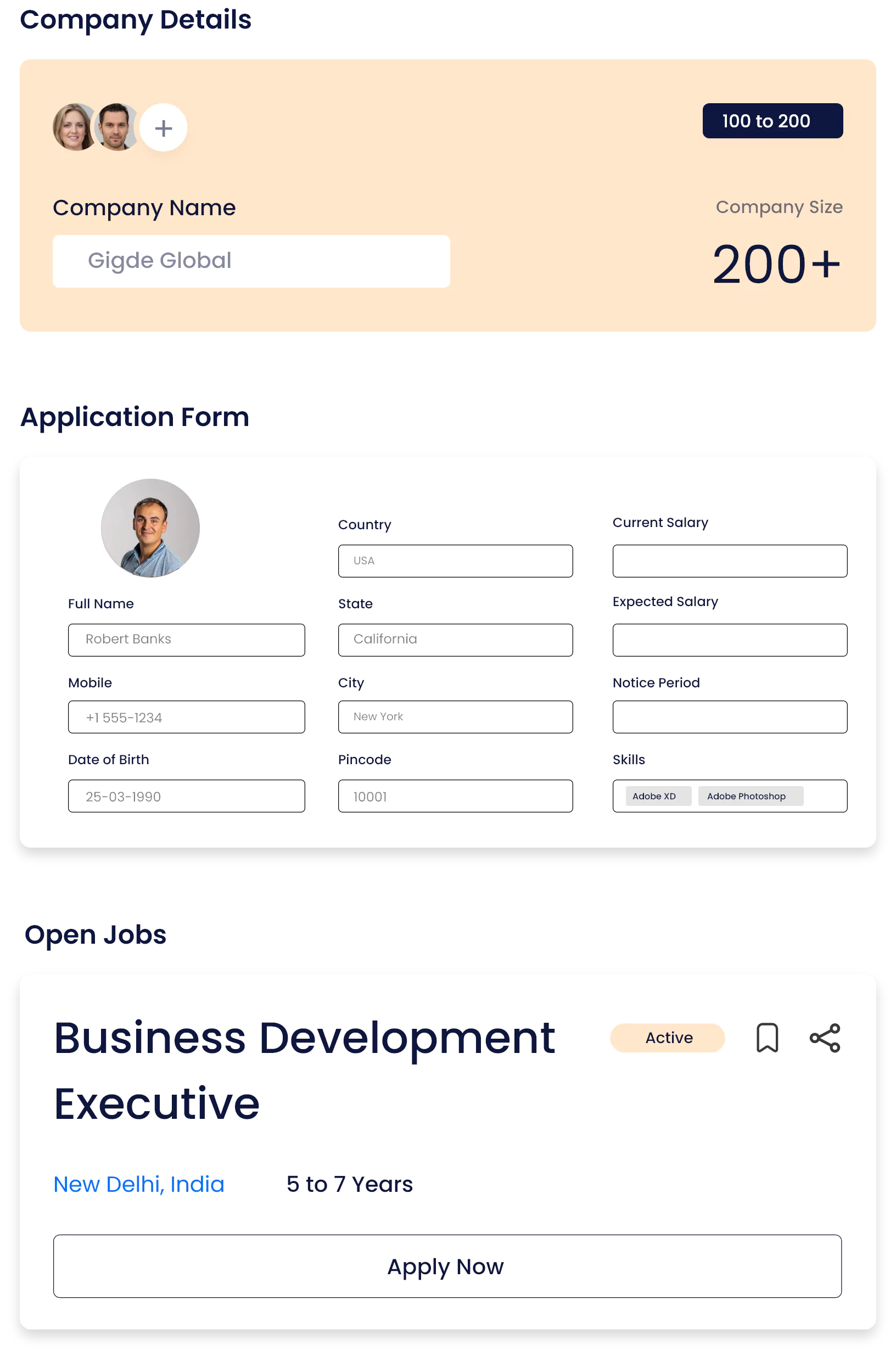
Streamline Talent Pipeline
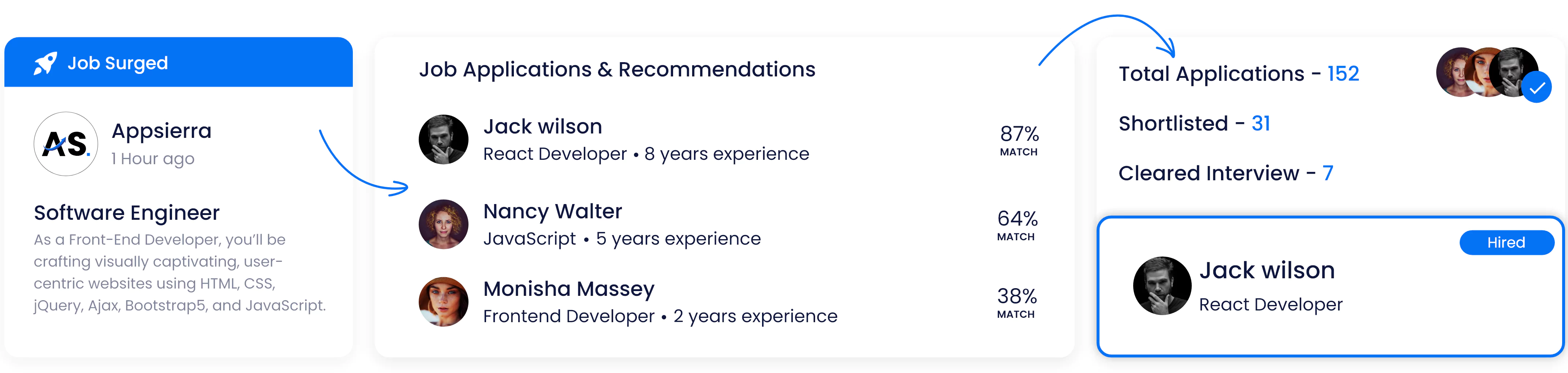
Get real-time insights and analytics on your candidates with our ATS!
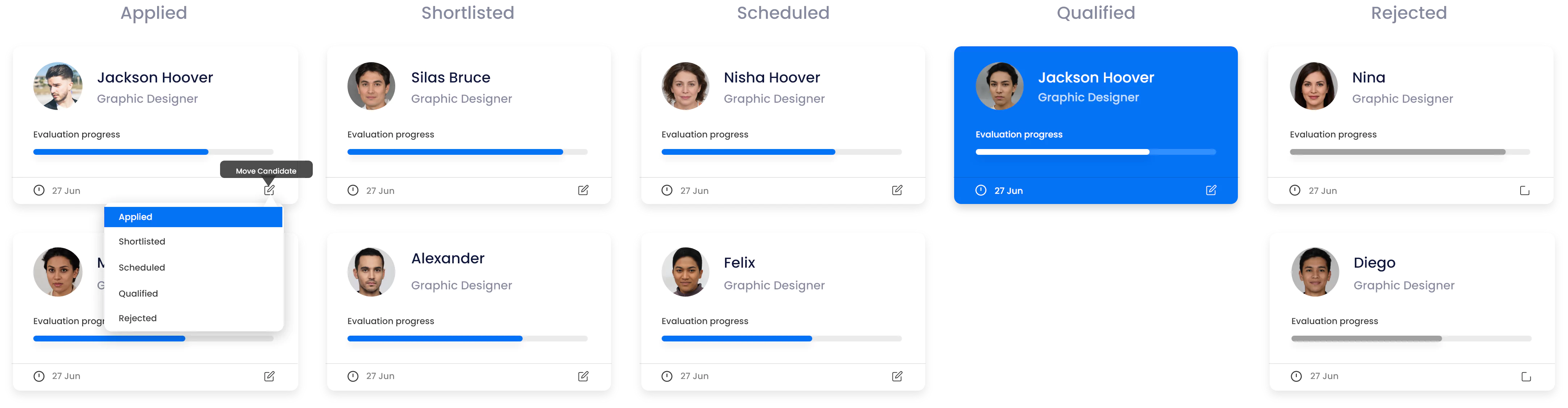
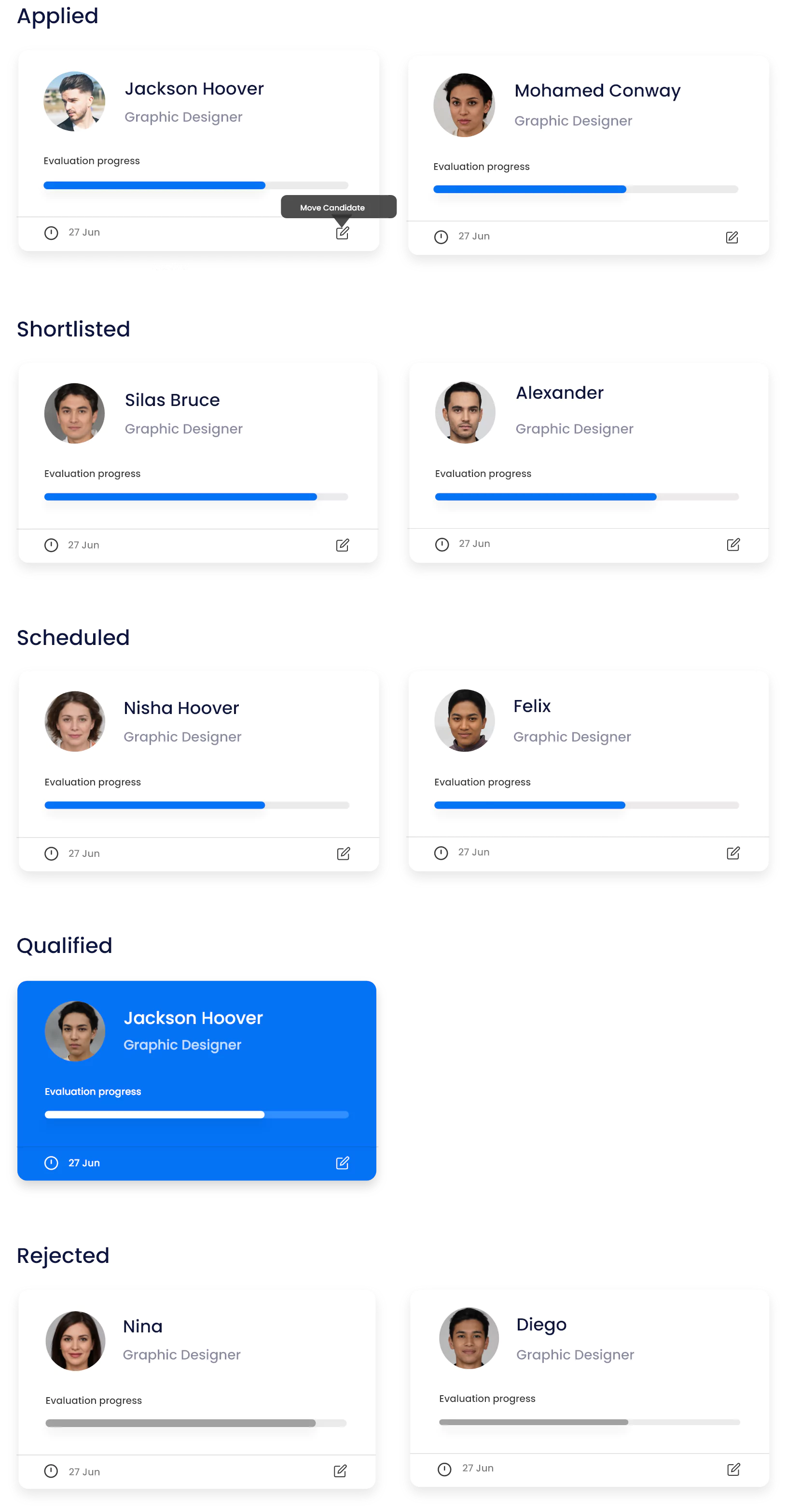
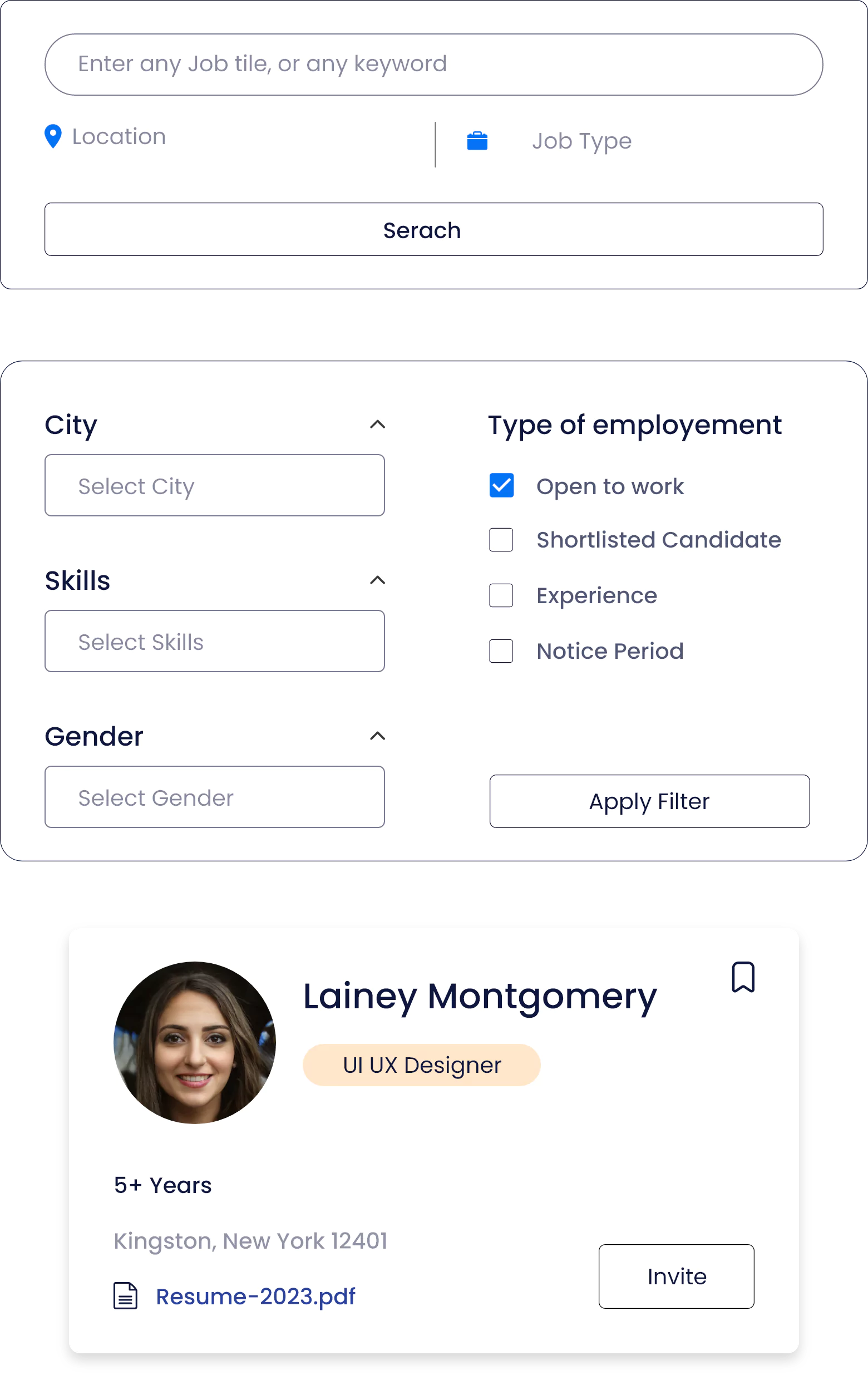
Recruit With Pitch N Hire’s Vast Candidate Pool
Access a world of talent. Leverage Pitch N Hire's comprehensive candidate pool to search for the most perfect match for your open roles. From different backgrounds and also skill sets, we connect you with the best candidates prepared to raise your team.
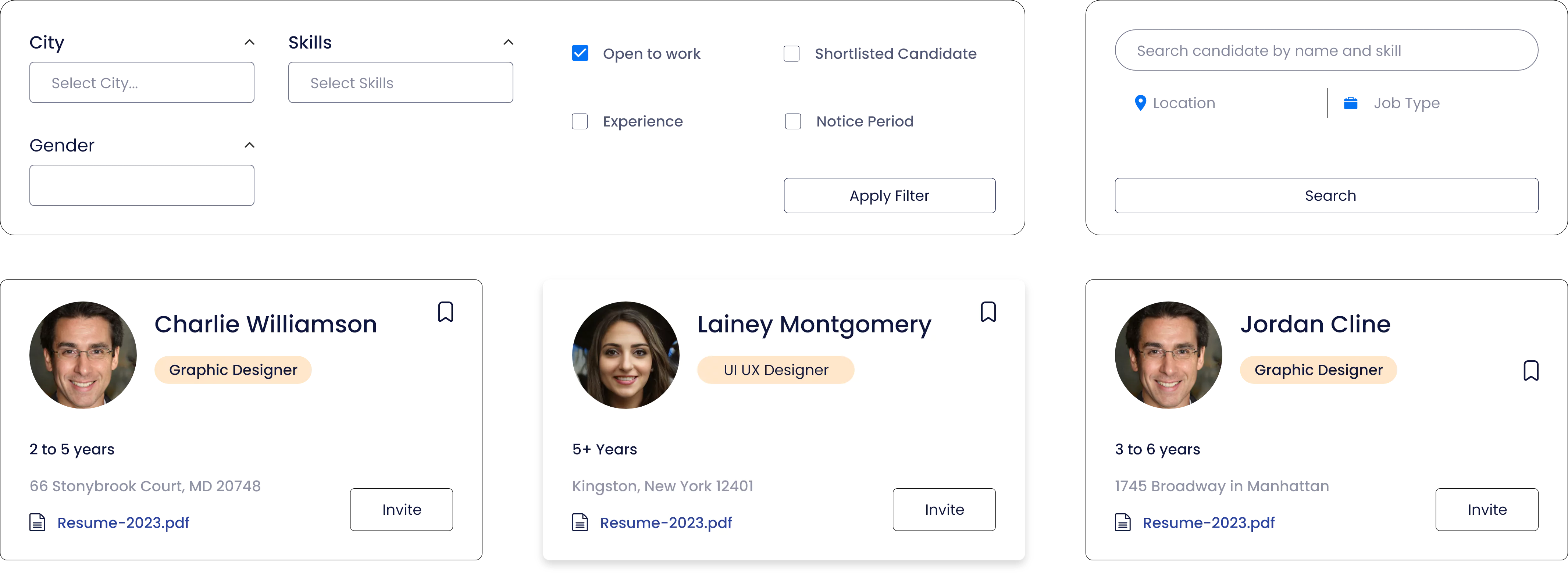
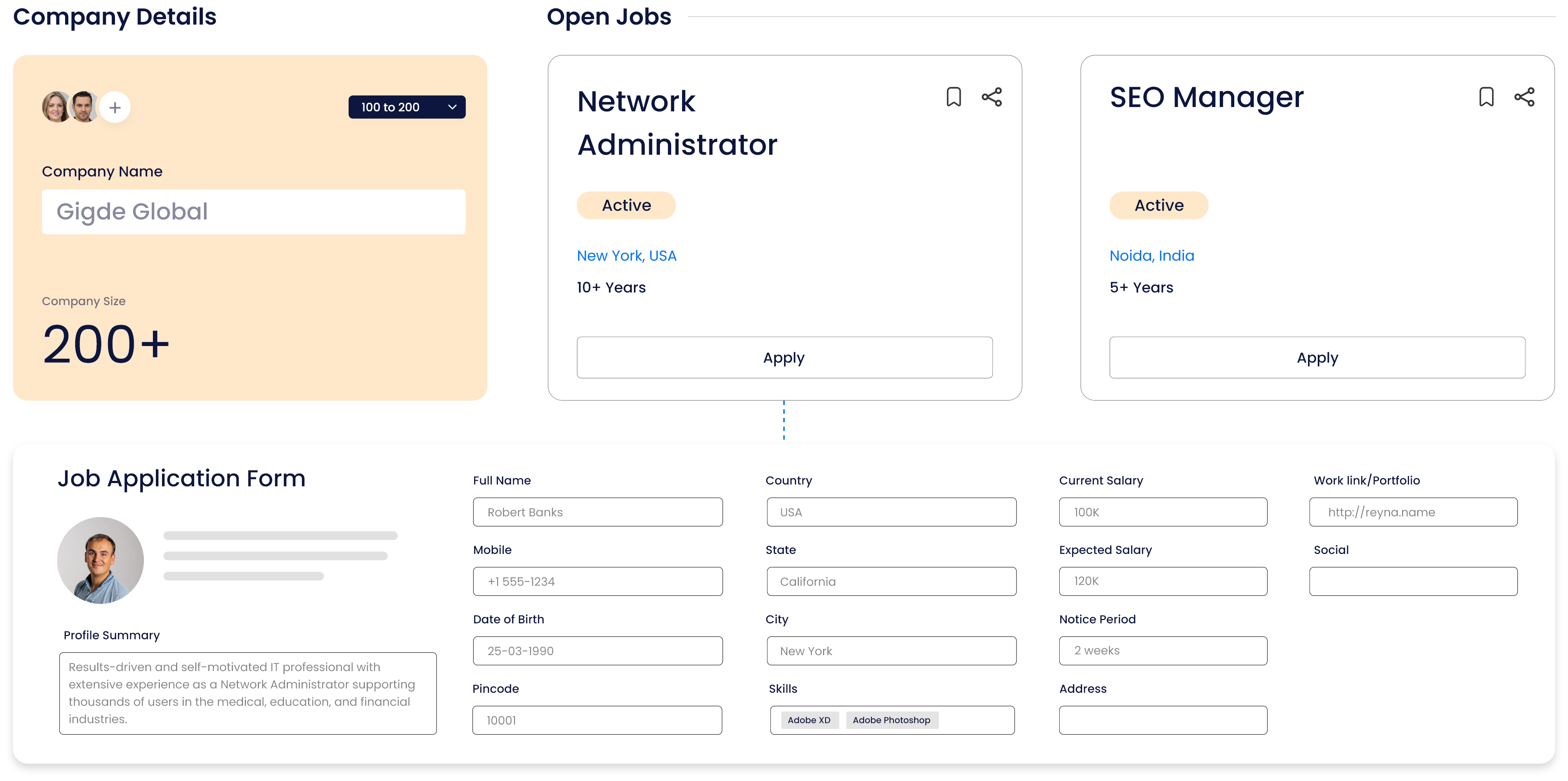
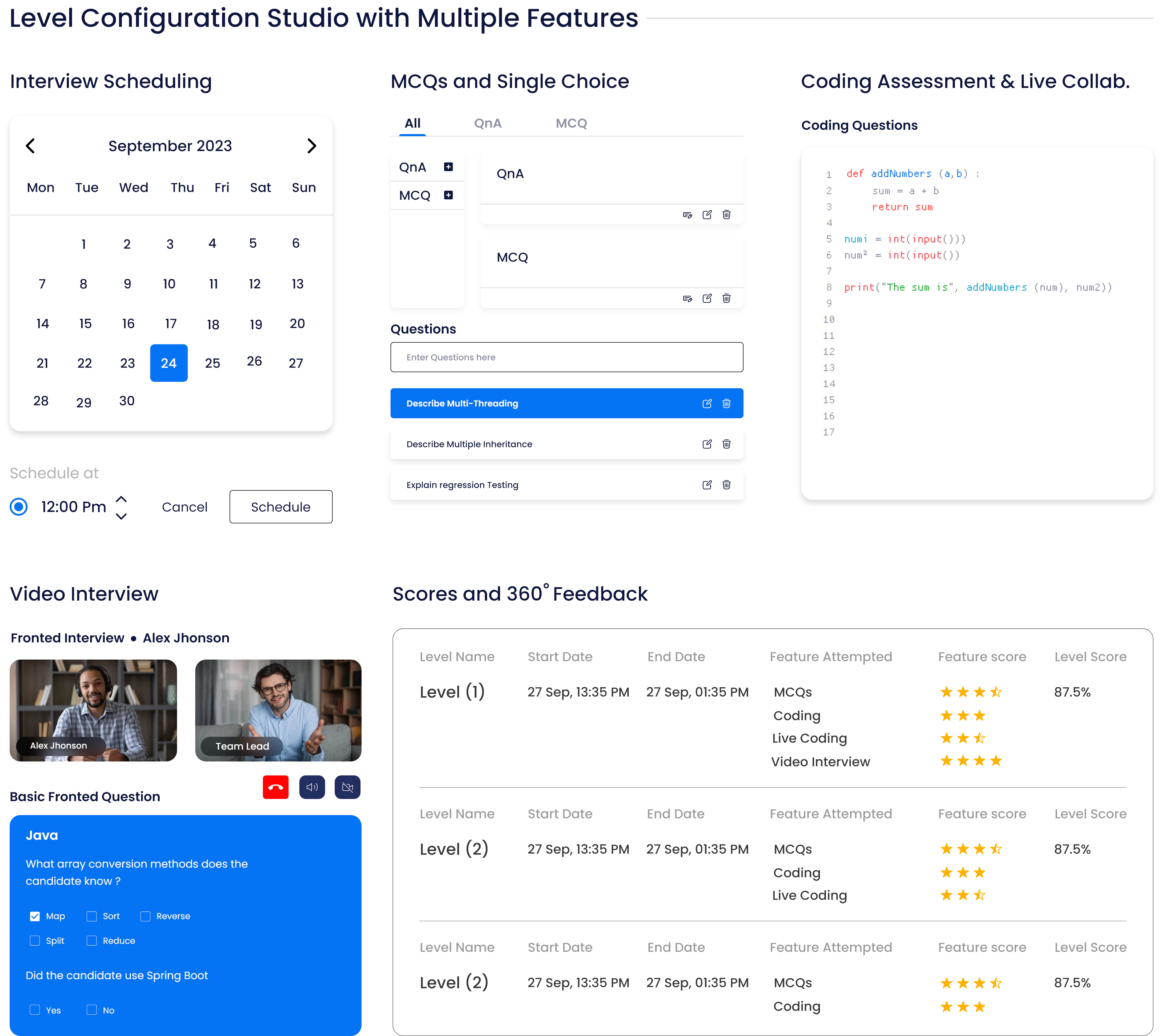
Assess candidates in real-time with our MCQ, Live Coding & integrated Video Calling
Evaluate functional capabilities, domain knowledge, and proficiency with MCQ, Video Calling and Live Coding Simulations. Our comprehensive skill assessments cover a wide range of modern-day skills and coding languages across various functions and roles. Enhance your campus hiring program with our engaging and data-backed assessment solution.







Integrate with your Favourite products
With an ATS that fits!









